笔者在最开始学习知识+AI时感到有些困惑,因为直观来看,基于知识or外部规则的约束,似乎应该是确定性的,类似if-else那种判断的约束。因此,把一个规则or知识图谱表示进机器学习模型里好像有些“画蛇添足”。
但经过一段时间的学习后笔者明白了这一领域的具体思想,所谓知识嵌入的神经网络,即学习一个知识的表示,通过模型训练优化这个表示,最终达到将知识“融入”模型的效果。这一过程是比较“软性”的,哪怕是下面提到的规则注入,也是一种类似正则化项的软约束。
因此,这篇文章中笔者总结了几种常见的知识嵌入方法,对每种方法,直接给出一个简单的示例代码小例子,从而帮助理解这一方法和具体的实现。
核心思想
目标:将结构化知识(如知识图谱、规则、领域约束)融入神经网络,提升模型性能或可解释性。
常见方法:
- 知识图谱嵌入(Knowledge Graph Embedding, KGE):将知识图谱中的实体和关系映射为低维向量。
- 规则注入(Rule Injection):通过损失函数或网络结构,强制模型遵循逻辑规则。
- 图神经网络结合知识(GNNs with Knowledge):利用图结构传递知识信息。
环境准备
1
2
3
4
| import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
|
示例1:知识图谱嵌入
任务:将知识图谱中的实体和关系映射为向量,捕捉语义关联。
代码实现:(TransE算法)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| class TransE(nn.Module):
def __init__(self, num_entities, num_relations, embedding_dim):
super(TransE, self).__init__()
self.entity_emb = nn.Embedding(num_entities, embedding_dim)
self.relation_emb = nn.Embedding(num_relations, embedding_dim)
nn.init.xavier_uniform_(self.entity_emb.weight)
nn.init.xavier_uniform_(self.relation_emb.weight)
def forward(self, head, relation, tail):
h = self.entity_emb(head)
r = self.relation_emb(relation)
t = self.entity_emb(tail)
score = torch.norm(h + r - t, p=2, dim=1)
return score
model = TransE(num_entities=5, num_relations=2, embedding_dim=10)
head = torch.tensor([0, 1])
relation = torch.tensor([0, 1])
tail = torch.tensor([1, 2])
positive_score = model(head, relation, tail)
negative_tail = torch.tensor([3, 4])
negative_score = model(head, relation, negative_tail)
loss = torch.relu(positive_score - negative_score + 1.0).mean()
print("TransE Loss:", loss.item())
|
关键解释:
- 实体和关系被编码为向量,通过
h + r ≈ t的约束建模知识图谱中的三元组。
- 损失函数鼓励正样本得分低于负样本,实现知识嵌入。
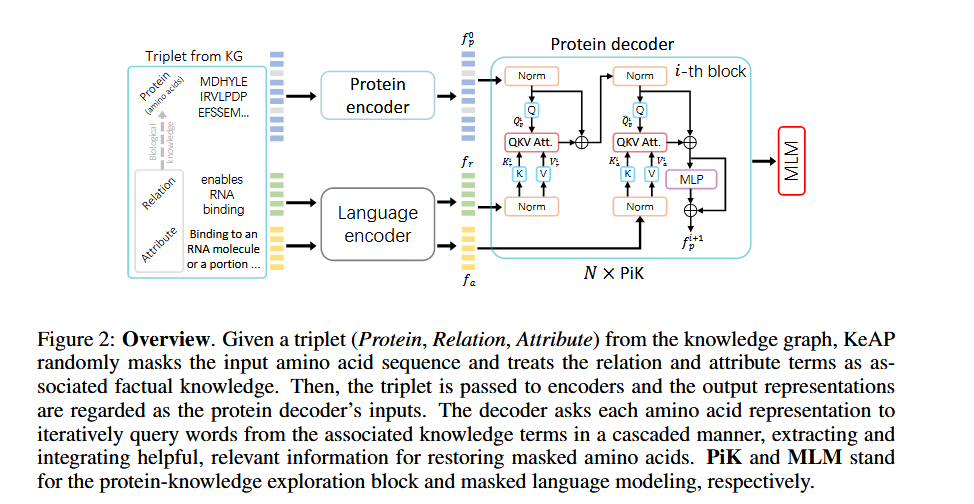
当然,现在对于知识图谱的嵌入,也有很多新方法,比如下图这篇论文 (ICLR23)就将知识图谱嵌入到了encoder里,再通过自注意力查询机制来进行优化
示例2:规则注入(通过损失函数约束)
任务:在分类任务中强制模型遵循逻辑规则(如“如果A成立,则B必须成立”)。
代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| class RuleConstrainedModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(RuleConstrainedModel, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
def rule_loss(outputs):
prob_class0 = torch.sigmoid(outputs[:, 0])
prob_class1 = torch.sigmoid(outputs[:, 1])
violation = torch.relu(prob_class0 - 0.5) * torch.relu(prob_class1 - 0.3)
return violation.mean()
model = RuleConstrainedModel(input_dim=10, hidden_dim=20, output_dim=2)
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(100):
inputs = torch.randn(32, 10)
labels = torch.randint(0, 2, (32,))
outputs = model(inputs)
ce_loss = nn.CrossEntropyLoss()(outputs, labels)
r_loss = rule_loss(outputs)
total_loss = ce_loss + 0.5 * r_loss
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
|
关键解释:
- 通过自定义的
rule_loss将领域规则融入训练目标。
- 模型在优化过程中同时拟合数据和满足规则。
示例3:图神经网络结合知识(GCN整合知识图谱)
任务:在图卷积网络(GCN)中整合知识图谱的邻接矩阵。
代码实现(使用PyTorch Geometric):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
import torch_geometric
from torch_geometric.nn import GCNConv
class KnowledgeGCN(nn.Module):
def __init__(self, num_features, hidden_dim, num_classes):
super(KnowledgeGCN, self).__init__()
self.conv1 = GCNConv(num_features, hidden_dim)
self.conv2 = GCNConv(hidden_dim, num_classes)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = torch.relu(x)
x = self.conv2(x, edge_index)
return x
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='/tmp/Cora', name='Cora')
data = dataset[0]
model = KnowledgeGCN(num_features=dataset.num_features, hidden_dim=16, num_classes=dataset.num_classes)
optimizer = optim.Adam(model.parameters(), lr=0.01)
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = nn.CrossEntropyLoss()(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")
|
关键解释:
- 知识图谱的拓扑结构通过
edge_index传递到GCN中。
- 节点特征和知识图谱的邻接关系共同影响节点表示学习。
知识嵌入的核心技术总结
| 方法 |
适用场景 |
优点 |
缺点 |
| 知识图谱嵌入 |
关系推理、推荐系统 |
显式建模实体关系 |
对复杂关系建模能力有限 |
| 规则注入 |
强领域约束任务(如医疗、法律) |
确保模型行为符合先验知识 |
规则设计依赖专家经验 |
| 图神经网络 |
图结构数据(社交网络、分子) |
自然融合图结构知识 |
计算复杂度高,需图数据支持 |
进一步探索方向
- 动态知识嵌入:根据输入动态选择相关知识(如注意力机制)。
- 多模态知识融合:结合文本、图像、图谱等多源知识。
- 可解释性分析:通过嵌入的知识反向生成解释(如激活可视化)。
希望本教程能帮助你直观理解知识嵌入的核心思想!