OS笔记
南京大学蒋炎岩老师《操作系统》课程笔记,AI时代的操作系统课
绪论
一个重塑全人类的 prompt:
我在做 [X]。如果你是一位专业人士,有更好的方法和建议吗?尽可能全面。
操作系统:管理软/硬件资源、为程序提供服务
A body of software, in fact, that is responsible for making it easy to run programs (even allowing you to seemingly run many at the same time), allowing programs to share memory, enabling programs to interact with devices, and other fun stuff like that. (OSTEP)
应用视角的操作系统
程序是个状态机,但有些东西单靠程序本身无法实现。
“纯粹的计算” 只能改变程序内的状态,但有些 API 涉及到 “程序外的状态”,这就和操作系统有关了
操作系统最大的职责就是让我们在编程时感受不到操作系统的存在——我们在编程时想象程序 “独占整个计算机,逐条指令执行”,大部分时候都不用 “考虑” 操作系统的存在。当系统调用发生时,程序执行被完全暂停,但操作系统依然在工作——就像麻醉后醒来,周围的环境发生了变化,但我们完全没有感到时间的流逝。by jyy
任何程序 = minimal.S = 状态机
- 总是从被操作系统加载开始
- 通过另一个进程执行 execve 设置为初始状态
- 经历状态机执行 (计算 + syscalls)
- 进程管理:fork, execve, exit, …
- 文件/设备管理:open, close, read, write, …
- 存储管理:mmap, brk, …
- 最终调用 _exit (exit_group) 退出
硬件视角的操作系统
硬件根本不知道有没有操作系统:
我就是个无情执行指令的状态机
- 见什么指令执行什么指令
下层不需要知道上面怎么用,只管 “无情地提供服务”
- 系统调用支撑应用程序
- 指令集支撑高级语言程序
操作系统就是一个普通的 (二进制) 程序:
- 接管了中断、I/O、……
- 应用程序不能直接访问
- 把应用程序 “放” 到 CPU 上运行一会
- 中断后,操作系统又开始执行
- (操作系统启动后,操作系统就变成了一个中断处理程序)
刚刚遗漏的一个细节:
CPU = 无情执行指令的机器
- 从 CPU Reset 开始执行
- 从 Mem[PC] 取指令
- 译码、执行,如此往复
那么,Reset处的代码是什么呢?
答案:系统厂商的代码
- 把一个特殊的存储器 memory-map 到 CPU Reset 后的代码
- 这段代码 “出生” 就有机器完整的控制权
从固件到操作系统:
- 40年前的约定是,固件(BIOS)判断磁盘的前512字节(MBR, master boot record, 主引导扇区)是否可加载,然后将其内容加载到内存的0x7c00,因此如果你写一个简单的汇编程序在这里,固件就会先加载MBR,然后你的汇编程序再加载大的操作系统进来
- 我们可以“调试”这个过程,从而看到固件加载MBR的过程
python中,使用os.system执行命令和在命令行执行命令一样,也会有相同的命令行中的输出,如果需要输入中途确认信息,程序会暂停
数学视角的操作系统:
- 程序是个状态机,硬件也是个状态机,操作系统就是个状态机管理器。
- 朴素的想,可以通过状态机建模和遍历,实现对软件正确性的证明。
虚拟化
One of the most fundamental abstractions that the OS provides to users: the process
- 把物理计算机 “抽象” 成 “虚拟计算机”
- 程序好像独占计算机运行
程序和进程
- 程序是状态机的静态描述
- 描述了所有可能的程序状态
- 程序 (动态) 运行起来,就成了进程 (进行中的程序)
UNIX 的进程管理:
- 复制状态机: fork()
- 复位状态机: execve()
fork:立即复制状态机
- 包括所有状态的完整拷贝
- 寄存器 & 每一个字节的内存
- Caveat: 进程在操作系统里也有状态: ppid, 文件, 信号, …
- 小心这些状态的复制行为
- 复制失败返回 -1
如何区分呢?
- 新创建进程返回 0
- 执行 fork 的进程返回子进程的进程号——“父子关系”
理解fork:两个例子:
1 | // 第一个例子,来自OSTEP,很好的描述了fork的基本原理 |
1 | // 一个非常tricky的例子,来自课件 |
例子2的关键点:缓冲机制与 fork() 的交互:
- 缓冲模式:
- 终端:行缓冲(
\n触发刷新)。 - 管道/文件:全缓冲(缓冲区满或程序结束才刷新)。
- 终端:行缓冲(
fork()复制缓冲区:- 子进程会复制父进程的未刷新缓冲区,导致多次输出相同内容。
同时,必须注意的是,fork之后,如果不加限制,子进程和父进程的执行顺序是没有约定的,下一行代码可能是父进程先执行,也可能是子进程先执行,这中不确定性可能导致很多问题,将在并发模块详细讨论。
但是如果加上一个wait()系统调用,那就确定了,wait的行为是:
This system call won’t return until the child has run and exited. Thus, even when the parent runs first, it politely waits for the child to finish running, then wait() returns, and then the parent prints its message.
(下面这部分与OS主线内容无关)
除了写到环境变量里,API_KEY放到哪更安全?(可以使用SOPS对配置文件数据进行加密,回头试试)
在不同shell里执行enecve env,输出的结果是不同的:
不同 Shell 对
execve的隐式处理(如自动添加PWD、SHLVL、_等变量)。// 直接这样指定就可以不带任何你自己没有传入的环境变量 char *const argv[] = { "/bin/env", NULL, };1
2
3
4
5
6
7
8
9
10
---
#### execve:复位状态机
> a successful call to exec() never returns
```c
int execve(const char *filename,
char * const argv[], char * const envp[]);
核心行为:
execve 是一个 进程映像替换(Process Image Replacement) 的系统调用,其行为规则是:
- 成功调用时:
- 当前进程的代码、数据、堆栈等会被完全替换为新的程序(此处是
/bin/bash)。 - 原进程的后续代码(包括
printf)不再执行,因为原进程的映像已被覆盖。
- 当前进程的代码、数据、堆栈等会被完全替换为新的程序(此处是
- 失败调用时:
execve返回-1,并设置errno表示错误原因。- 程序继续执行后续代码(即
printf)。
execve 是唯一能够 “执行程序” 的系统调用:
- 因此也是一切进程 strace 的第一个系统调用
进程的地址空间
每个进程都 “拥有” 自己的内存——我们可以用 new/delete 管理它们。但进程的内存是哪里来的?一个指针
p到底能指向什么?管理地址空间的系统调用: mmap 给我们答案。
从进程的初始状态说起:
寄存器
- (之前观察过一次)
- 这个好办,直接打印出来就行了
内存
- 这个有点难办
- 我们可以把任何整数 cast 成指针
- 用工具,看真实系统
- 向AI老师学习,AI可以为我们生成
statedump.py脚本,查看内存映射
观测后的发现:不是所有的系统调用都要中断交给内核(如映射中的vvar, vdso区)
vdso和vvar:
vdso是一个共享库,包含可以直接在用户空间调用的函数。vvar是vdso函数所需的数据来源,存储内核维护的变量或数据结构。- 当用户空间程序调用
vdso中的函数(如gettimeofday)时,vdso会从vvar中读取数据,而无需进入内核模式。
使用场景:
- 性能优化:
vdso和vvar减少了频繁系统调用的开销,特别适用于高频率的时间获取操作。 - 简化开发:用户空间程序可以直接调用
vdso中的函数,而无需关心底层系统调用的细节。
多想一想:关于进程的初始状态
- 只有ELF 文件里声明的内存和一些操作系统分配的内存
- 任何其他指针的访问都是非法的
- 如果我们从输入读一个 size,然后 malloc(size)
- 内存从拿来呢?
一定有一个系统调用可以改变进程的地址空间!
Memory Map系统调用:在状态机状态上增加/删除/修改一段可访问的内存
1 | // 映射 |
mmap 的主要作用包括:
- 文件映射
- 将文件内容映射到进程的虚拟内存中,从而实现对文件的高效读写(避免频繁的
read/write系统调用)。 - 例如,可以将一个大文件映射到内存中,直接通过指针访问文件内容。(或者把可执行文件加载到内存,就可以运行了(后面讲加载器还会再讲))
- 将文件内容映射到进程的虚拟内存中,从而实现对文件的高效读写(避免频繁的
- 共享内存
- 使用
MAP_SHARED标志,多个进程可以共享同一块内存区域,用于进程间通信(IPC)。
- 使用
- 匿名内存分配
- 使用
MAP_ANONYMOUS标志,可以分配一块匿名内存区域,类似于malloc,但更灵活。
- 使用
进程 (状态机) 在 “无情执行指令机器” 上执行
- 状态机是一个封闭世界
- 但如果允许一个进程对其他进程的地址空间有访问权?
- 意味着可以任意改变另一个程序的行为
- 听起来就很 cool
- 意味着可以任意改变另一个程序的行为
“入侵” 进程地址空间的例子
- 调试器 (gdb)
- gdb 可以任意观测和修改程序的状态
- 金山游侠(游戏外挂)
怎样入侵?
- 一切皆文件,直接修改 /proc/[pid]/mem
- ptrace系统调用
访问操作系统对象
前言:
操作系统还必须给应用程序提供访问操作系统对象的机制。当然,这可以直接以 API 的形式提供,例如 Win32 API 包含 “RegOpenKeyEx” 访问注册表。但我们主要关注 UNIX 的 “Everything is a file” 访问操作系统对象的机制,以及这一机制带来的方便 (和不便)。
文件描述符
文件:有 “名字” 的数据对象
- 字节流 (终端,random)
- 字节序列 (普通文件)
文件描述符
- 指向操作系统对象的 “指针”(所以名字起的不好,并不是什么描述信息)
- Everything is a file
- 通过指针可以访问 “一切”
文件描述符的分配:总是分配最小的未使用描述符
- 0, 1, 2 是标准输入、输出和错误
- 新打开的文件从 3 开始分配
- 文件描述符是进程文件描述符表的索引
- 关闭文件后,该描述符号可以被重新分配
- have a try,看看具体分配和重新分配的规律
文件描述符是 “进程状态的” 的一部分
- 保存在操作系统中;程序只能通过整数编号访问
- 文件描述符自带一个 offset
Quiz: fork() 和 dup() 之后,文件描述符共享 offset 吗?
- 这就是 fork() 看似优雅,实际复杂的地方
- have a try
- 通过AI编写的代码,事实证明是的
对比:Linux中的文件描述符和Windows中的handle
windows是更面向工程的设计
- 默认 handle 是不继承的 (和 UNIX 默认继承相反)
- 可以在创建时设置 bInheritHandles,或者运行时修改
- “最小权限原则”(更注重安全,而unix是hack风格:joy:)
- lpStartupInfo 用于配置 stdin, stdout, stderr
访问操作系统中的对象
文件描述符是用来访问对象的指针,操作系统提供了用来创建对象的API,比如mount
通过mount挂载,相当于创建了可以访问的文件描述符对象
dup命令
任何“可读写”的东西都是文件!
管道:一个特殊的 “文件” (流)
- 由读者/写者共享
- 读口:支持 read
- 写口:支持 write
1 | // 匿名管道 |
- 返回两个文件描述符
- 进程同时拥有读口和写口
- 如果读口得不到东西,就等待(前提是写端也是打开的,不能说写段中途被关闭,这样写口的关闭被读口检测到,读口也会结束读取)
- 管道规则:当管道的所有写端被关闭时,
read()会返回0(表示 EOF),而不是无限阻塞。- 此时子进程的
read(fd[0], ...)会立即返回0,子进程继续执行后续代码(打印空数据并退出)。
- 此时子进程的
一切皆文件的优劣
- 优雅,文本接口,就是好用
- 和各种 API 紧密耦合
- 对高速设备不够友好
- 额外的延迟和内存拷贝
- 单线程 I/O
本讲总结:
操作系统必需提供机制供应用程序访问操作系统对象。对于 UNIX 系统,文件描述符是操作系统中表示打开文件 (操作系统对象) 的指针;而 Windows 则更直接地提供了 handle 机制。
终端和 UNIX Shell
从打字机时代->键位为什么是现在这样的?到电传打字机到模拟终端,终端终究是一个人机交互的设备
/dev/pts(伪终端从设备)、/dev/ptmx(伪终端主设备)
pty:伪终端
伪终端的核心结构
伪终端由一对“设备”组成:
- 主设备(PTY Master):
- 由终端模拟器(如
GNOME Terminal、xterm或SSH 客户端)控制。 - 负责从用户输入(如键盘)接收数据,并将数据发送到从设备。
- 同时接收从设备的输出(如程序的执行结果),并显示给用户。
- 由终端模拟器(如
- 从设备(PTY Slave):
- 连接到实际运行的程序(如
bash、python等)。 - 程序认为自己是在和真实的终端通信,但实际上是通过伪终端与主设备交互。
- 连接到实际运行的程序(如
1 | +----------------+ 双向管道 +----------------+ |
1 | import os |
/dev/tty和/dev/pts有什么区别?为什么tty显示的是/dev/pts(tty现在代表的好像是控制终端)
openpty(): 通过 /dev/ptmx 申请一个新终端,everything is a file,这也是操作系统中的对象。
- 这也能间接看出一切皆文件的一点坏处,就是如果linux里面有/dev/ptmx,开发者就倾向不用api直接访问文件,但是这种代码就是不可移植的
终端和操作系统
程序是个状态机,除了内部的内存和寄存器状态,以及之前介绍的进程状态pid,ppid,还有sid,pgid,uid,……,因此进程状态非常复杂,这个状态机大的超乎想象
我们有那么大一棵进程树,都指向同一个终端,有的在前台,有的在后台,Ctrl-C 到底终止哪个进程?
解决方案:

给进程引入一个额外编号 (Session ID,大分组)
- 子进程会继承父进程的 Session ID
- 一个 Session 关联一个控制终端 (controlling terminal)
- Leader 退出时,全体进程收到 Hang Up (SIGHUP)
再引入另一个编号 (Process Group ID,小分组)
通常由同一个命令行触发的进程及其子进程组成,这个PGID通常是进程组首进程(第一个创建的进程)的 PID
管道命令
ls | grep "file" | wc -l会创建一个进程组,包含ls、grep和wc三个进程。只能有一个前台进程组
操作系统收到 Ctrl-C,向前台进程组所有进程发送 SIGINT
- (真累……但你也想不到更好的设计了)
一个进程id的例子:(这里是先挂起了两个python和一个vim,然后使用ps命令)
1 | PID PPID PGID SID TT COMMAND |
- stty -a: 你可以看到按键绑定 (奇怪的知识增加了)
- fg %i(恢复/切换)“最小化” = Ctrl-Z (SIGTSTP)
- 最大化,最小化,关闭按钮,都早在命令行终端就实现了
创建一棵进程子树的实验,更多的细节:按ctrl+c,不管有没有托孤,进程都会退出(说明进程退出不是看pid,而是有追踪pgid的方法)
从这两节课讲的各种设备其实让我们看到了系统的复杂性:
- 系统构建总是走向屎山,因为不可能预见未来的需求,同时你的基础设施用的人太多了,根本不能做减法
C 标准库和实现
在操作系统 API 之上,为了服务应用程序,毋庸置疑需要有一套 “好用” 的库函数。虽然 libc 在今天的确谈不上 “好用”,但成就了 C 语言今天 “高级的汇编语言” 的可移植地位,以 ISO 标准的形式支撑了操作系统生态上的万千应用。
libc简介
C 语言:世界上 “最通用” 的高级语言
- C 是一种 “高级汇编语言”
- 作为对比,C++ 更好用,但也更难移植
- 系统调用的一层 “浅封装”
libc:语言机制上的运行库
- 大部分可以用 C 语言本身实现
- 少部分需要一些 “底层支持”
- 例子:体系结构相关的内联汇编
libc库也被标准化
- ISO IEC 标准的一部分
- POSIX C Library 的子集
- 稳定、可靠 (不用担心升级版本会破坏实现)
- 极佳的移植性:包括你自己的操作系统!
基础编程机制的抽象
看看perror,env和jyy的调试过程
系统调用和环境的抽象
反复出现的 “No such file or directory”
- 这不是巧合!(是由于出错时设置了不同的错误标志位)
- 我们也可以 “山寨” 出同样的效果
- Quiz: errno 是进程共享还是线程独享?
- 线程有一些我们 “看不到” 的开销:ucontext, errno, …
内存管理
使用的系统调用:mmap (历史:sbrk)
- 大段内存,要多少有多少
- 用 MAP_ANONYMOUS 申请
- 超过物理内存上限都行 (Demo)
操作系统不支持分配一小段内存
- 这是应用程序自己的事
- 应用程序可以每次向操作系统 “多要一点” 内存
- 自己在内存上实现一个数据结构
实现malloc(n):
如果n足够大
- 直接用 mmap 分配内存
如果n不够大
- 从一个 mmap 得到的内存池中分配
- 我们有一个大区间 [L,R)
- 维护其中不相交的小区间集合
- 啊!太好了!这是个数据结构问题……
- 最简单想法:free list(低效)
- Interval tree 可以实现 O(logn) 的分配/回收
可执行文件
(静态链接) 可执行文件的概念和基本原理;我们如何自己动手构建一个可执行文件格式。
ELF:Executable and Linkable Format
可执行文件是进程初始进程状态的描述
回顾:System V ABI
- Section 3.4: “Process Initialization”
- 只规定了部分寄存器和栈
- 其他状态 (主要是内存) 由可执行文件指定
“可执行文件” 需要包含什么?
- (今天先假设不依赖 “动态链接库”)
- 基本信息 (版本、体系结构……)
- 内存布局 (哪些部分是什么数据)
- 其他 (调试信息、符号表……)
ELF文件:一个经典、没有任何问题的设计,但:
- ELF 不是一个人类友好的 “状态机数据结构描述”
- 为了性能,彻底违背了可读 (“信息局部性”) 原则
CRIU:项目状态存储和迁移工具,利用了core dump。(做一个core dump并迁移不难,但是操作系统还保留了一部分当前执行文件的信息,这部分信息的取得和迁移,冲突避免等就很有挑战了)
- 在AI agent时代就太有用了
Funny Little Executable
计算机是人造的科学,随时问一句:如果是我来设计,会怎样做?有想法就能实现
ELF这种文件并不神秘,它就是一个“数据结构”
动态链接和加载
动态链接
为什么要有动态链接:
- 实现运行库和应用代码分离
- 运行库和应用代码还可以分别独立升级
- 可以用 ldd 命令查看
- 大型项目的分解
- 改一行代码不用重新链接 2GB 的文件
如果 Linux 应用世界是静态链接的……
- libc 紧急发布安全补丁 → 重新链接所有应用
- Semantic Versioning
- “Compatible” 是个有些微妙的定义
- “Dependency hell”
mmap 和虚拟内存
一个实验:
- 构造一个非常大的 libbloat.so
- 我们的例子:100M of nop (0x90)
- 创建 1,000 个进程动态链接 libbloat.so 的进程
- 观察系统的内存占用情况(
vmstat or free -h)- 100MB or 100GB?
结论:只读方式 mmap 同一个文件,物理内存中只有一个副本。进程的地址空间(mmap+进程号查看,会发现每个进程都以为自己有一个libbloat.so),实际是分页机制维护的 “幻象”
更多的结论:(可以通过观察gcc –static和不加static选项的a.out来观测)
- a.out (动态链接) 的第一条指令不在程序里
- 可以 starti 验证 (在 ld.so 里)
- 这是 “写死” 在 ELF 文件的 INTERP (interpreter) 段里的
- (我们甚至可以直接编辑它)
- a.out 执行时,libc 还没有加载
- 可以 info proc mappings (pmap) 验证
- libc 是用 mmap 系统调用加载的
- 可以 strace 验证
Virtual Memory:
- 操作系统维护 “memory mappings” 的数据结构
- 这个数据结构很紧凑 (“哪一段映射到哪里了”)
- 延迟加载
- 不到万不得已,不给进程分配内存
- 写时复制 (Copy-on-Write)
- fork() 时,父子进程先只读共享全部地址空间
- Page fault 时,写者复制一份
- fork() 时,父子进程先只读共享全部地址空间
实现动态链接
编译器在编译和汇编时,不知道一个函数是静态还是动态链接,因此,对于一个函数调用,编译器只能生成短跳转。
链接器会判断出这个函数是不是动态链接的,如果是,则在 a.out 里 “合成” 一段小代码:
1 | printf@plt: jmp *PRINTF_OFFSET(%rip) |
这就是PLT (Procedure Linkage Table)!
得到PLT中的信息后,再去全局偏移表(GOT, Global Offset Table)中获取存放外部的函数地址的数据。
延迟绑定的实现机制:
在 Linux 系统中,延迟绑定是通过 PLT(Procedure Linkage Table,过程链接表) 和 GOT(Global Offset Table,全局偏移表) 实现的:
- PLT:存储跳转到 GOT 的代码。
- GOT:存储函数实际地址的表格。
- 动态链接器:在函数第一次被调用时,动态链接器会解析函数的实际地址并更新 GOT。
但是PLT没有解决数据的问题:(这段内容不用掌握)
对于
extern int x,我们不能 “间接跳转”!数据访问必须立即解析地址,因为 CPU 指令需要确定的内存地址来执行读/写操作。(否则每次数据访问都查表,性能无法忍受)
函数调用可以延迟绑定,因为跳转指令可以通过 PLT/GOT 间接实现。
不优雅的解决方法
- -fPIC 默认会为所有 extern 数据增加一层间接访问
__attribute__((visibility("hidden")))
LD_PRELOAD:一个神奇的 “hook” 机制
- 允许 “preload” 一个自己的库
- 当然,没有魔法
- LD_PRELOAD 会传递给 ld-linux.so
- 我们可以在运行时,用一个自己的库替换掉某个库:(比如替换malloc/free,更好的观察内存分配)
1 | LD_PRELOAD=./mylib.so ./a.out |
LD_PRELOAD的核心原理:
- 动态链接器(如
ld-linux.so)在加载程序时,会按以下顺序搜索符号(函数/变量):- LD_PRELOAD 指定的库 → 2. 程序的依赖库 → 3. 系统默认库(如
libc.so)。
- LD_PRELOAD 指定的库 → 2. 程序的依赖库 → 3. 系统默认库(如
- 如果多个库定义了相同的符号,LD_PRELOAD 的库优先级最高,其函数会被调用。
构建应用生态
(本讲科普性质)
除了对象和系统调用API:
The last piece: “初始状态”
- Everything is a state machine
- “操作系统中的对象” 应该也有一个初始状态
它是什么呢?
- 观察到 Linux 的系统更新
- “update-initramfs… (漫长的等待)”
- 这就是 Linux Kernel 启动后的 “初始状态”
我们的 initramfs(最小的initramfs)
- 可以只有一个 init 文件
- 可以是任意的 binary,包括我们自己实现的
- (系统启动后,Linux 还会增加 /dev 和 /dev/console)
- 需要给 stdin/stdout/stderr 一个 “地方”
initramfs: 并不是我们看到的Linux世界
启动的初级阶段
- 加载剩余必要的驱动程序,例如磁盘/网卡
- 挂载必要的文件系统
- Linux 内核有启动选项 (类似环境变量)
- /proc/cmdline (man 7 bootparam)
- 读取 root filesystem 的 /etc/fstab
- Linux 内核有启动选项 (类似环境变量)
- 将根文件系统和控制权移交给另一个程序,例如 systemd
启动的第二级阶段
- 看一看系统里的 /sbin/init 是什么?
- 计算机系统没有魔法 (一切都有合适的解释)
可以自己接管这一切:
创建一个磁盘镜像
- /sbin/init 指向任何一个程序
- 同样需要加载必要的驱动
- 例子:pivot_root 之后才加载网卡驱动、配置 IP
- 例子:tty 字体变化
- 这些都是 systemd 的工作
- 例子:NOILinux Lite
Initramfs 会被释放
- 功成身退
期中回忆
每年期中时间和考题变化很大,所以下面东西仅仅为参考,我们这年是学完虚拟化考的。
四个简答(40)
为什么Ctrl+C不能退出有的程序、a.out加载到内存的初始状态栈里面都有什么,mmap系统调用的作用,什么是文件描述符
一个分析题,主要和fork相关(30)
- fork时候,文件描述符和偏移量会被怎么复制
- fork程序的分析
一个代码题(30),主要是文件相关的系统调用
- 如果重定向文件描述符之前不清空缓冲区,会有什么后果
- 设计函数
create_child,实现把子进程的标准输入绑定到父进程的标准输出
并发
多处理器编程
进程在 read() 等操作等待 I/O 时可能还可以同时完成其他任务,以及硬件逐渐有了多个 CPU 处理器……进程级的并行显得有些 “不太够用”。我们需要一个新的机制,能让多个执行流共享内存——于是就有了线程。
入门:共享内存线程模型与线程库
什么是线程:共享内存的进程
多线程程序的状态机模型
- 增加一个特殊的系统调用:spawn()
- 增加一个 “状态机”,有独立的栈,但共享全局变量
- 状态迁移:选择一个状态机执行一条语句 (指令)
- Let’s do it with model checker
然而还有很多值得深入思考的问题:(都可以用AI来构造例子)
多线程程序真的利用了多处理器吗?
- 并发确定了,那是不是真并行?
线程是否具有独立堆栈?
- 如果是,栈的范围?
如何用 gdb 单步调试多线程程序?
但是既然并发如此好用,代价是什么?代价就是我们需要重新理解 “编程”。
放弃:确定性
虚拟化使进程认为 “世界上只有自己”
- 除了系统调用,程序的行为是 deterministic 的
- 初始状态 (argv, envp) 一样、syscall 行为一样,程序无论运行多少次,结果都是一样的
并发打破了这一点
- 并发程序每次 non-deterministically 选一个线程执行
- 这意味着 load 可能读到其他线程的 store (也可能不)
- 非确定性的程序理解起来相当困难
- 连1+1都不会求了(下面例子)
1 |
|
另一个例子:并发执行三个 T_sum,sum 的最小值是多少?
1 | void T_sum() { |
Model Checker: sum = 2
- 注意不是 1 (因为循环了 3 次)
- (Trace recovery is NP-Complete.)
这体现了“数学视角” 的价值
- Nondeterminism 对人类来说是本质困难的
- 证明才是解决问题的方法
- ∀线程调度,程序满足 XXX 性质
放弃:顺序
让我们来看看编译器的行为,和在并发之前编译器所遵循的基本假设:
虚拟化:进程只需要看到自己和操作系统
- Determinism: 除了系统调用,没人能 “干涉” 程序的状态
编译器:按照 “系统调用” 优化程序
- 语句/指令不需要按程序声明的那样执行
- 典型的优化:死代码消除 (dead code elimination)
- 只要保证优化前后的程序在系统调用层面上等价,可以任意调换/删除语句
- 但这和 non-determinism 是矛盾的
- load 可能会读到来自其他线程写入的值
- 如果依赖这个假设编程,编译器会教你做人的
- 但这和 non-determinism 是矛盾的

放弃:一致性(感觉也算顺序的一种)
我们简化理解多处理器的状态机模型时假设了每次选择一个处理器执行一条指令。然而,由于动态指令调度和缓存的共同作用,实际程序的运行结果更可能超出我们的预期。
三种内存模型:
| 内存模型 | 允许的重排序 | 典型硬件/语言支持 |
|---|---|---|
| 顺序一致性 (SC) | ❌ 全部禁止 | C++ seq_cst、Java volatile |
| x86 (TSO) | ✅ Store-Load | Intel/AMD CPU |
| 宽松模型 (ARM/Power) | ✅ Load-Load, Load-Store, Store-Store | ARM/PowerPC、C++ relaxed |
允许重排:允许Store-Load重排就是指原本先store再load的指令,现在可能顺序反过来。
因此硬件实际执行时,可能和编译器一样,对指令做改变。
1 | int x = 0, y = 0; |
比如这个例子,实际执行可能打印出0 0.
同时再次强调命令行工具的使用:
./test-rmo | head -n 100 | sort | uniq -c
并发控制:互斥
想想Load/store 指令是瞬间完成且生效的不成立的时候,Peterson算法为什么不对
使用原子指令实现互斥
cli (x86)
Clear Interrupt Flag
- eflags 里有一个 bit 是 IF (0x200)
- 对于单处理器系统,死循环 = 计算机系统卡死
适用条件
- 单处理器系统、操作系统内核代码(用户程序没有cli的执行等级,即使有,在多处理器中,cli的代价太大了)
自旋锁:思路其实非常简单,就是下面的模型:
1 | void lock() { |
因此只要硬件提供原子指令,保证这个判断是原子的就行。
使用系统调用实现互斥
自旋锁的问题:Scalability
系统随着需求或负载增加时,依然能够保持性能和稳定性,灵活扩展资源的能力。(另一个角度:在资源增长时,能维持或提升性能的能力)
性能问题 (1)
除了获得锁的线程,其他处理器上的线程都在
空转
- “一核有难,八核围观”
- 如果代码执行很久,不如把处理器让给其他线程
性能问题 (2)
- 应用程序不能关中断……
- 持有自旋锁的线程被切换
- 导致 100% 的资源浪费
- (如果应用程序能 “告诉” 操作系统就好了)
- 你是不是想到了什么解决方法?
解决方法:把锁的实现放到操作系统里就好啦
syscall(SYSCALL_acquire, &lk);- 试图获得 lk,但如果失败,就切换到其他线程
syscall(SYSCALL_release, &lk);- 释放 lk,如果有等待锁的线程就唤醒
- 剩下的复杂工作都交给内核
- 关中断 + 自旋
- 自旋锁只用来保护操作系统中非常短的代码块
- 成功获得锁 → 返回
- 获得失败 → 设置线程为 “不可执行” 并切换
- 关中断 + 自旋
1 | // 与自旋锁完全一致,且性能足够好 |
并发控制:同步1(条件变量)
互斥确保了代码块按照某个顺序执行,但,互斥并不总是能满足多个并发线程协作完成任务的需求,我们很多时候还需要控制代码块执行的先后次序。如何能便捷地让共享内存的线程协作以共同完成计算任务?
互斥似乎还不够
- 互斥实现了原子性:A→BA→B 或 B→AB→A
- 但没有给我们确定性:A→BA→B
理解并发的方法
- 线程 = 我们自己
- 共享内存 = 物理空间
条件变量的正确打开方式
经典问题:生产者消费者问题
“条件变量”是万能的同步方法,只要明确这个线程做这件事的condition是什么就能实现同步
1 | // 这里的cond = depth < n |
并发控制:同步2(信号量)
信号量是从互斥锁中衍生出来的
sleepsort的时间复杂度?
order violation
并发bugs
死锁:
AA型死锁:一个线程本身,连续上了两次锁
ABBA型死锁:T1:lock(A), lock(B) T2: lock(B), lock(A)。
回头看看视频的最后20min,原子性违反到最后那一段
在所有并发bugs中,最严重也最容易犯的就是data race
真实世界的并发编程(1)
本讲科普性质,从三部分讲解真实的并发例子
高性能计算
源自数值密集型科学计算任务
物理系统模拟
- 天气预报、航天、制造、能源、制药、……
- 大到宇宙小到量子,有模型就能模拟
物理世界具有 “空间局部性”
- “模拟物理世界” 的系统具有 embarrassingly parallel 的特性
通常计算图容易静态切分 (机器-线程两级任务分解)
- 生产者-消费者解决一切
Web开发
Challenges
- 线程 (在 1990s) 开销很大
- 连程序都写不利索的人,让他并发编程?
于是有了 event-based concurrency (动态计算图)
- 禁止任何计算节点并行 (和高性能计算完全不同的选择)
- 允许网络请求、sleep 在后台执行
- 执行完后产生一个新的事件 (计算节点)
- 假设网络访问占大部分时间;浏览器内计算只是小部分
- 事件可以在浏览器里看到!
- 允许网络请求、sleep 在后台执行
JavaScript 的并发模型基于 Event Loop,它的工作流程如下:
- 主线程 执行同步代码(如
console.log)。 - 遇到 异步操作(如
setTimeout、fetch、fs.readFile),交给 底层系统(如浏览器 API 或 Node.js 的 libuv)处理,不阻塞主线程。 - 异步操作完成后,回调函数 被放入 任务队列(Task Queue)。
- Event Loop 不断检查 调用栈(Call Stack)是否为空:
- 如果为空,从任务队列取出回调执行。
1 | [主线程] → [异步API] → [任务队列] → [Event Loop] → [主线程] |
历史的车轮:PC → Web → Web 2.0 (UGC) → AI (AGI)
“框架” 是驱动技术发展的原动力
我们需要好的抽象来表达人类世界中的需求
简单可靠
,聚集大量行业开发者
- AI 也许是这里的 “开发者”
灵活通用,构造各种应用程序
数据中心
“A network of computing and storage resources that enable the delivery of shared applications and data.” (CISCO)
以海量分布式数据 (存储) 为中心
- 实时的 “小数据处理”
- 内容分发、用户认证、视频直播、弹幕……
- 离线的 “大数据处理”
- 内容索引、数据挖掘……
今天的解决方法:Serverless Computing: 我才不管并发呢
- Function as a Service (FaaS): 系统自动 scale 到 C10M
- 大号的 JavaScript 程序 (但没有 shared memory)
- 需要 idempotence
协程:操作系统不感知的上下文切换
和线程概念相同
进程内独立堆栈、共享内存的状态机
但 “一直执行”,直到 yield() 主动放弃处理器
- yield() 是函数调用
- 只需保存/恢复 non-volatile 的寄存器
- (线程切换需要保存/恢复全部寄存器)
- 但 sleep (I/O) 时,所有协程都 “卡住了”
- 失去了并行
- yield() 是函数调用
同一个操作系统线程中执行
- 可以由程序控制调度
- 除了内存,不占用额外操作系统资源
GO:为数据中心而生的语言
提供了高 I/O 并发的基础机制和 goroutine 之间的同步机制
小孩子才做选择,多处理器并行和轻量级并发我全都要!
Goroutine: 概念上是线程,实现是线程和协程的混合体
真实世界的并发编程(2)
- RTX 5080: 10,752 CUDA Cores
- 这是怎么做到的?
- 它们也 (可以) 是 shared memory 啊!
Single instruction, multiple threads:
- 一个 PC (program counter) 管多个线程
- 假设(3,0), (3,1), (3,31)都被分配到了同一个 core 上
- map[3 * 1920 + 0] = t;
- map[3 * 1920 + 1] = t;
- map[3 * 1920 + 31] = t;
- 魔法发生了!Memory coalescing(多个线程能够同时访问连续的内存地址,从而提高内存访问效率)
- 假设(3,0), (3,1), (3,31)都被分配到了同一个 core 上
(通过这个机制,我没有做任何多余的事情,但是天然实现了向量的指令集)
持久化
设备和驱动程序
不应该让程序直接控制设备,而是提供适当的抽象
把设备抽象成文件和数据接口,程序只要使用文件操作就可以操纵设备
操作系统提供从“文件操作”到“设备操作”的转换(设备驱动程序)
但是,设备并不是只有数据这一部分,还有配置
配置是设备真正复杂的地方
“非数据” 的设备功能几乎全部依赖 ioctl
- “Arguments, returns, and semantics of ioctl() vary according to the device driver in question”
可以问问AI ioctl可以操作什么设备的功能?
“万物皆文件”,你可以用read, write, ioctl这三个系统调用实现所有的设备,任何的功能。但是代价是ioctl这个系统调用超级复杂
存储设备原理
存储系统上面是文件系统,平时打交道的都是文件系统,越过文件系统的抽象直接接触存储系统是很少的
为什么能实现二叉树,原则上就能实现一切数据结构?
只要用任何一种方法区别两种状态,就可以实现计算机世界的持久化
转动“自由度”的概念
磁存储
磁存储设备的进化:(更好的存储密度,提高随机读写性能)磁带——磁鼓——磁盘
磁盘:作为存储设备的分析
存储特性
- 价格低:高密度、低成本
- 容量高:2.5D,上万磁道
- 可靠性高 (高速运转的机械部件是潜在的威胁)
读写性能
- 顺序读写:较高
- 随机读写:勉强 (需要等待定位)
磁盘目前还是计算机系统的主力数据存储
为什么磁盘是从C口编号的?因为A和B是上个时代留给软盘的
软盘:把读写头和盘片分开——实现数据移动
- 计算机上的软盘驱动器 (drive) + 可移动的盘片
- 8” (1971), 5.25” (1975), 3.5” (1981)
- 最初的软盘成本很低,就是个纸壳子
- 3.5 英寸软盘为了提高可靠性,已经是 “硬” 的了
- 8” (1971), 5.25” (1975), 3.5” (1981)
挖坑存储
光盘:容量大且不易损坏,存储时间久,但是读速度一般,而且很难写(只能append only的写)
充电or放电
今天的版本答案
刚刚的两种存储设备,最大的问题就是:慢!
只要有机械设备,转的再快,在电子的面前也是很慢的
Flash Menory(闪存):在电路中挖坑,充放电决定1bit的状态
唯一的问题:放电做不到100%干净,放电数万次后就不能用了
为什么我们现在根本不担心?
答案:软件定义优盘,你的SSD,优盘,TF卡里藏了完整的计算机系统(CRTL, DRAM, NAND, FTL)SOC
FTL:flash translation layer
- Wear Leveling:用软件使写入变得均匀
存储设备与操作系统
block devices
文件系统看存储系统,其实就两个API,bread和bwrite
文件系统 API
本讲内容:操纵目录和文件系统的 API。
不同的链接
需求:系统中可能有同一个运行库的多个版本
libc-2.27.so,libc-2.26.so, …- 还需要一个 “当前版本的 libc”
- 程序需要链接 “
libc.so.6”,能否避免文件的一份拷贝?
- 程序需要链接 “
(硬) 链接:允许一个文件被多个目录引用
- 文件系统实现的特性 (ls -i 查看)
- 不能链接目录、不能跨文件系统
- 删除文件的系统调用称为 “unlink” (refcount–)
- 现在用 “万能” 的 unlinkat,也可以删除空目录
软链接:在文件里存储一个 “跳转提示”
软链接也是一个文件
- 当引用这个文件时,去找另一个文件
- 另一个文件的绝对/相对路径以文本形式存储在文件里
- 可以跨文件系统、可以链接目录、……
类似 “快捷方式”,几乎没有任何限制
- 链接指向的位置不存在也没关系
- (也许下次就存在了)
符号链接可以有很多神奇的作用:
- 做galgame
- “伪造”文件系统,新型的环境构建工具,如Nix
文件的元数据
文件作为OS中的对象,既然是对象,就有属性。ls -l查看
元数据:
- Type: d (directory), l (link), p (pipe), c (char), b (block)
- Mode: rwx (user, group, other)
- 例子:0o755 = rwx (111) r-x (101) r-x (101)
- Links: 引用计数 (硬链接,包括目录)
还会有更多额外的元数据,如Access control list(之后会专门讲)
更重量级的操作(辣椒)
OverlayFS: 一种联合文件系统,允许将多个目录 “层叠” 在一起,形成单一的虚拟目录。OverlayFS 是容器 (如 docker) 的重要底层机制。它也可以用于实现文件系统的快照、原子的系统更新等。
文件系统实现
FAT文件系统
DOS、mkfs.fat、看看课堂例子、
FAT总结:
- 性能:
- + 小文件简直太合适了
- -但大文件的随机访问就不行了
- 4 GB 的文件跳到末尾 (4 KB cluster) 有 220220 次 next 操作
- 缓存能部分解决这个问题
- 在 FAT 时代,磁盘连续访问性能更佳
- 使用时间久的磁盘会产生碎片 (fragmentation)
- malloc 也会产生碎片,不过对性能影响不太大
- 使用时间久的磁盘会产生碎片 (fragmentation)
- 可靠性:
- 维护若干个 FAT 的副本防止元数据损坏 (轻微写放大)
一些现在还在用FAT的应用:EFI文件、相机上的存储
UNIX 文件系统
文件系统的实现和内存中调度,如页表的实现是有区别的,(内存中没有特别显著的局部性特征)
B树就是一个ordered list?
Linux中的文件系统:ext2
局部性与缓存
- bitmap, inode 都有 “集中存储” 的局部性
- 通过内存缓存减少读/写放大
大文件 O(1)随机读写
- 支持链接 (一定程度减少空间浪费)
- inode 在磁盘上连续存储,便于缓存/预取
- 依然有碎片的问题
但可靠性依然是个很大的问题
- 存储 inode 的数据块损坏是很严重的
现代文件系统
其实就是根据各种实际的专用场景进行优化
观察在你想优化的场景下系统的特性-> 根据这些特性做定向优化
比如:闪存中存在写放大问题,随机读写较慢的问题
- 设计专门的Flash-Friendly Filesystem (f2fs)(把随机读写变成顺序读写,避免闪存不擅长随机读写)
总结:把文件系统理解成一个 “数据结构”,就不难理解经典和现代文件系统的设计理念——所有人都是在为了合适的硬件、合适的读写 workload 上,用合适的方式组织数据,维护树状 (和链接) 的目录结构和随机访问的文件操作。
持久数据的可靠性
实现可靠的磁盘
RAID:存储设备的虚拟化
- Redundant Array of Inexpensive (Independent) Disks (RAID)
- 把多个 (不可靠的) 磁盘虚拟成一块非常可靠且性能极高的虚拟磁盘
- 类比:进程/虚存/文件把 “一个设备” 虚拟成多份(一个“反向”的虚拟化)
崩溃一致性
- 所有的写请求都先到达缓存
- 计算机系统会按照他认为的 “最佳” 顺序写入
- 例子:HDD 的磁头运动规划
这将导致:磁盘掉电时,写入请求的顺序是没有任何保证的
FSCK 和 Journaling:实现崩溃一致性的机制
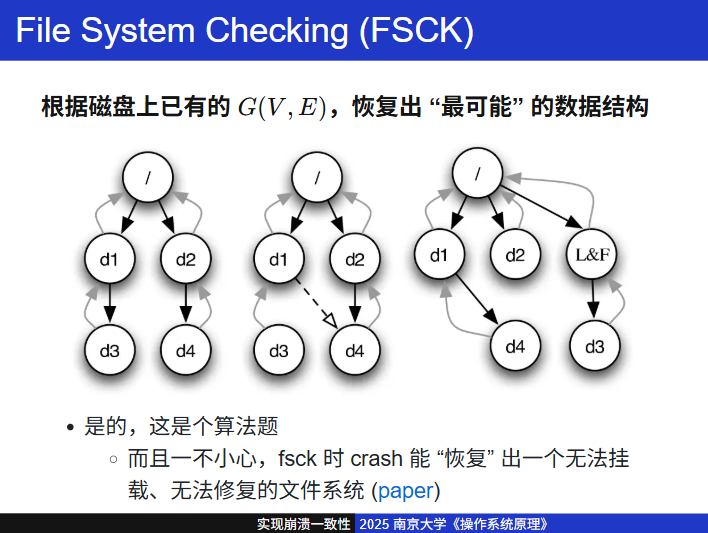
并发得到的历史教训:存储器是同样的 “乱序执行” 模型
- 不要实现 ad-hoc 的崩溃一致性
- 存储系统应该也提供一条fence指令
- 软硬协同实现崩溃一致性
- 目前存储系统提供的就是
bwrite bread bflush - 更底层的对这三个API的实现思路:LSM (Log-structured Merge Trees)、append-only+lazy update
注意bwrite/read/flush 是内核私有函数,用户态程序无权调用,用户态需用 write() + fsync() 实现类似功能。
sync() 系列系统调用:解决write返回了,但是文件没写到磁盘的问题
- sync: 同步所有文件系统中的所有数据
- 最强,等于 performance bug
- syncfs(fd): 同步 fd 对应的文件系统
- fsync(fd): 同步文件 data + metadata
- fdatasync(fd): 同步文件 data
- 最弱,但依旧可以控制 data loss (追加写可能丢失)
- API 设计者的难题:要不要再加一个 fddatasync() 呢?
总结: 存储系统支撑了当今的互联网工业——每个 SSD 都是 “套娃” 的计算机系统;它们又组成了大规模存储网络,再经过操作系统的 write-ahead logging、缓存等复杂的机制,最终为应用程序提供了一套简洁的文件系统 API,支撑了我们今天看到的数字世界
数据库与对象存储
关系型数据库
- Everything is a table
- 每行一个对象;对象可以用 id 索引其他对象
“ACID” 数据库
- A (Atomicity), C (Consistency), I (Isolation), D (Durability)
- Strong serializability: 查询结果 “按照某种顺序完成”
- Strong crash consistency: 系统 crash 也不会损坏或丢失
支持任意长 (允许混合任意计算) 的 Transaction
- 这个特性太重要了
ACID数据库的本质:学过《操作系统》就很好理解了
- 一把大锁保平安的效果
- 大规模并行执行的性能
- 完全自动的崩溃回复
- 应用数据交给数据库 = 一劳永逸; 甚至还可以 Hack
总结:在操作系统为我们提供的文件、目录、网络 API 上,开发者可以自由地创建更多、更复杂、更可靠的系统。我们看到了关系数据库的兴起,看到了云计算时代下 NoSQL 的繁荣,和今天的 AI 时代——在这几波浪潮之间,虽然操作系统内核的实现发生了巨大的变化,但操作系统的 API 相当惊人地稳定,这种 “稳定性” 支撑了应用生态的繁荣,这也是操作系统作为 “平台” 的使命
计算机系统安全
安全简介
- 不想给别人看的,别人就看不到:confidentiality
- 不想让别人改的,别人就改不了:integrity
- 属于我的,别人不能让我用不了:available
访问控制
进程 + 虚拟内存已经实现了隔离
访问控制:限制程序对操作系统对象的访问
- 拒绝越权访问 →→ Confidentiality
- 拒绝越权修改 →→ Integrity
- (再加上公平资源调度 →→ Availability)

更简单的机制:uid, gid, mode(用整数表达身份)
uid = 0→root, 其他都是 “普通用户”
- root 可以访问所有对象,也可以 setuid
- 子进程继承父进程的 uid
gid “完全自由” (虽然一般 0 是 root)
- 一个用户可以属于多个组
mode: r, w, x 的权限
- 例子:owner 只写不可读,audit 组可以读的日志文件
/etc/passwd:每行一个用户
- username:password:uid:gid:comment:home:shell
- 现代系统通常使用 shadow 文件存储密码的 hash
uid, gid, mode 并不是实现访问控制的唯一方法
- Access Control List (ACL)
- 基于 xattr 实现,支持为任意数量的用户和组设置权限
- SELinux/AppArmor
- sudo apparmor_status | ag –gpt -q Explain
- Capabilities
- capsh –drop=cap_net_raw – -c ‘ping 127.0.0.1’ (注意这是 fail on execve; getcap 查看 capabilities)
现代应用程序架构
进程 (运行的程序),一直以来都是操作系统中的核心抽象。作为应用程序的主体,运行它的方式却在多年的发展中历经了许多变化。
虚拟机和容器
容器的两个核心概念是namespace和cgroup
实现隔离:
- Linux namespaces: /proc/[pid]/ns/
- 将系统资源(如进程、网络、文件系统等)划分为独立的逻辑空间,使不同 Namespace 中的进程彼此隔离,仿佛运行在不同的系统中
- lsns 可以查看 (strace)
实现资源的控制:
- “圈一些进程”,设定资源使用策略
- 祝贺,你发明了 cgroups
- cat /proc/*/cgroup
- /sys/fs/cgroup
云时代的虚拟机:
- 容器就和虚拟机完全一样
- 开销比虚拟机低很多,安全性略低
- 这样不就可以在一台物理上部署更多的服务了吗?
- 黑心商人: 💰的机会来啦!
- 这样不就可以在一台物理上部署更多的服务了吗?
云原生与微服务
我们有容器 (虚拟机) 了
- 本来虚拟机里也是 HTTP Server (httpd)
- 干脆把程序拆成 Microservices?
- Cloud Native: 云会负责容器管理、API Gateway、负载均衡……
Serverless:容器的概念都可以不要了
Function as a service(FaaS)
你只需要实现 int foo() {}
剩下的都交给云厂商
- 黑心商人:都不需要 oversubscribe 了,直接按量计费,最大程度榨干机器性能
课程总结
我们有了推理模型
- o1 →→ o3-mini →→ deepseek-r1
- 用 token sequence 模拟 System II 是可以的
- 你是一个 Finite State Machine
- 但你有了纸和笔以后就是 Turing Machine 了
- 期待 tree-like memory based LLM ![😁]
- 感觉这个想法和张岳老师的内存有些相似,append only和search的结合,Tree search的利用
我看到了编程语言的未来
- Informal semantics of programming languages(写一句代码生成一个embeding,用于静态分析等?)(因为程序写出来那一刻其实包含了一些调用关系,是保存时候事后分析的时候丢失的)
- Monolithic programming
- 但似乎我只配做世界的观测者?